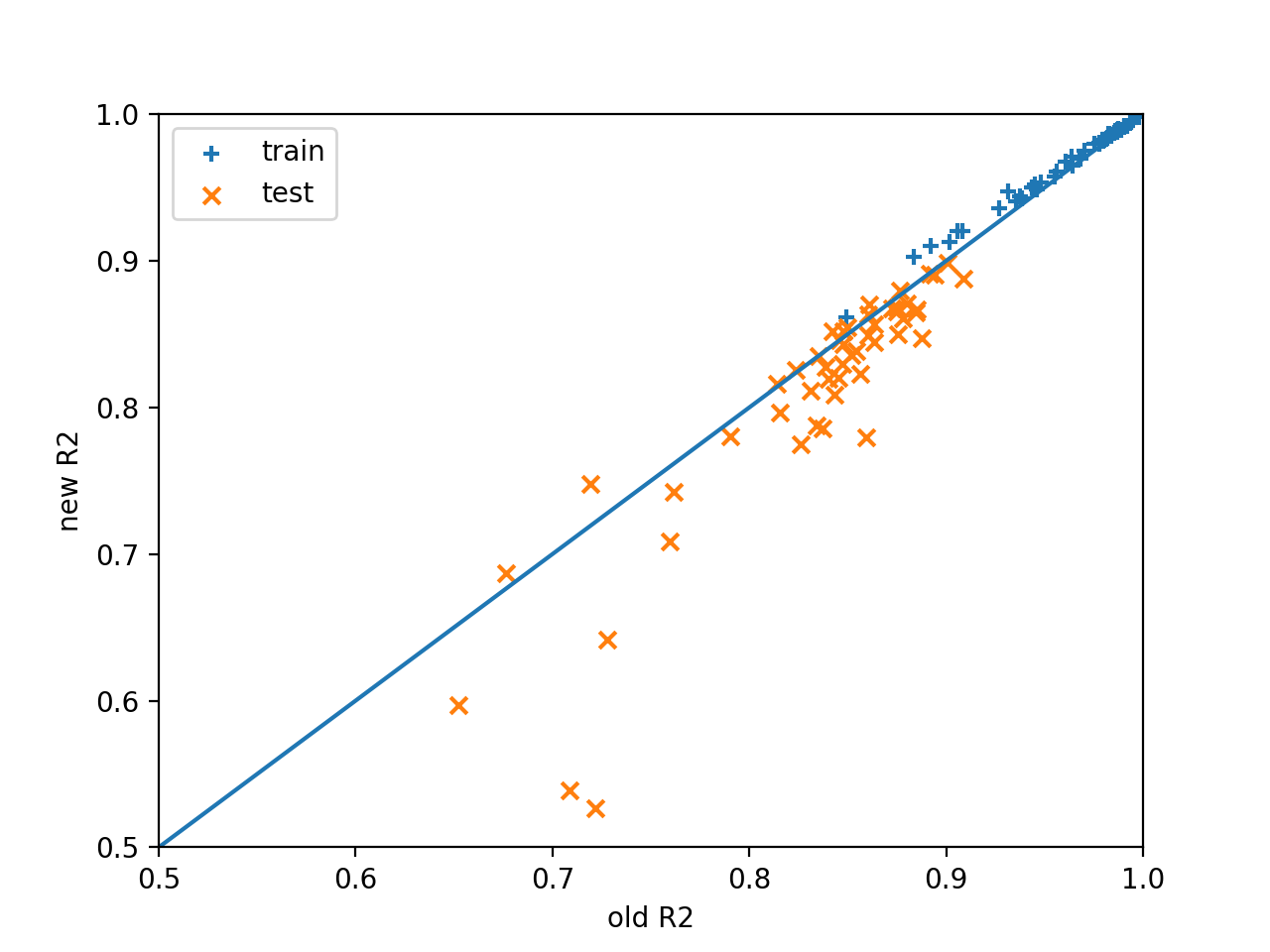
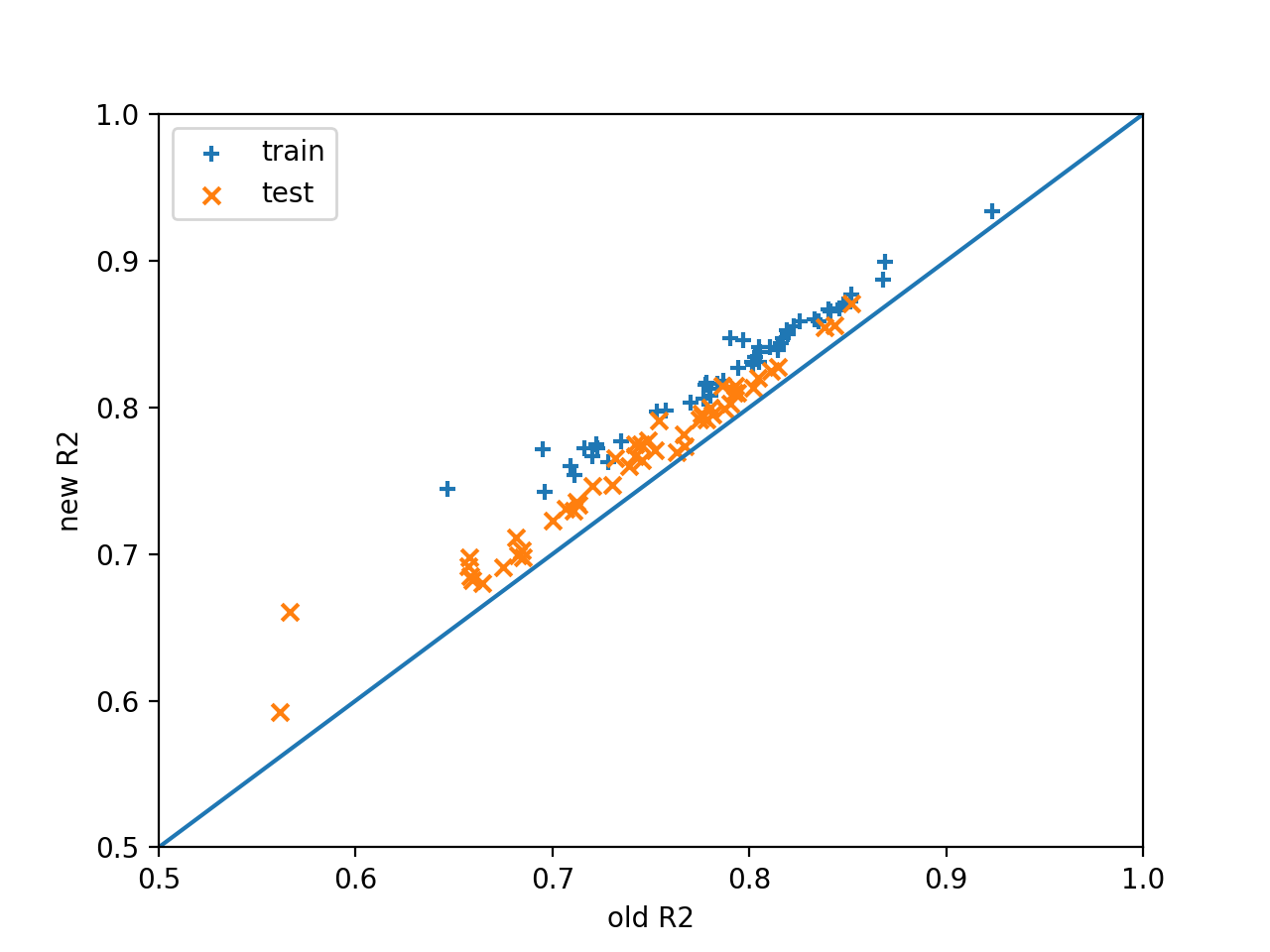
Two issues are currently found with the code:
- Sampling from some distributions are not implemented correctly,
- For beta, Chebyshev, shifting the distribution with
lowerandupperare not implemented. - For truncated gaussian, skewness and kurtosis values seems to not be properly implemented (should be non-zero in general?)
- Checks against invalid distributional parameter values (e.g.
shape_Aandshape_Bfor beta) and raise suitable errors when encountering invalid parameters - Clarifying the relation between
lower,upperandbounds(internal to the distribution class)
- Currently, for user defined meshes, in
_set_points_and_weights()inpoly.py. Along with_set_weightsinsampling_template.pythe design matrixAis set effectively with
wts = 1.0/np.sum( P**2 , 0)
quadrature_weights = wts * 1.0/np.sum(wts)
W = np.mat( np.diag(np.sqrt(quadrature_weights)))
A = W * P.T
which results in the design matrix having entries
A[i,j] = \frac{\phi_j(x_i)}{\sqrt{\sum_{k=1}^P \phi^2_k(x_i)}}
However, the correct conditioning should be
A[i,j] = \frac{\phi_j(x_i)}{\sqrt{\sum_{l=1}^N \phi^2_j(x_l)}} \approx \frac{\phi_j(x_i)}{\sqrt{\int \phi^2_j(x)~\rho~dx} }
A fix to the above code would be
quadrature_weights = 1.0/np.sum( P**2 , 1)
W = np.mat( np.diag(np.sqrt(quadrature_weights)))
A = P.T * W
Note the post-multiplying by W instead of pre-multiplying. We need to take care not to break other quadrature methods, so there will need to be some further modifications somewhere else.