In previous blog posts we have discussed the implementation of “model-aware” decision trees in Effective Quadratures (Polynomials Trees: Structure and Splitting) . These are trees that perform a model evaluation at each potential split location in the data and up to this point have been the only avaliable option in the PolyTree class.
While these tree models can produce results comparable with the accuracy of other state of the art regression tree models, they do have drawbacks. Firstly they are very computationally expensive to generate given that they require a polynomial to be fitted at every split candidate, often taking several minutes to build on my laptop. Secondly our current implementation greedily adds nodes, which results in trees that are unnecessarily complex and therefore often over-fit the data.
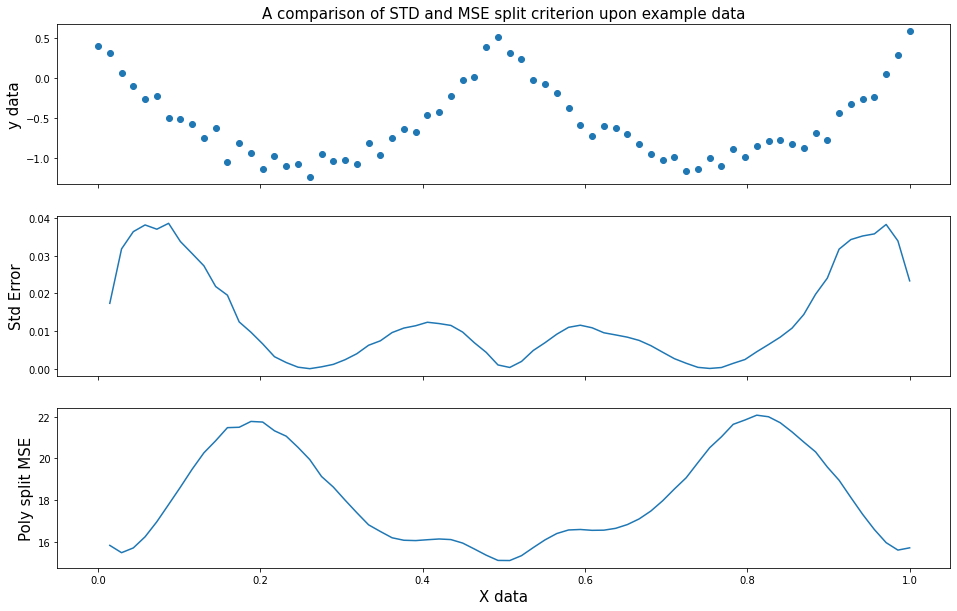
As an alternative to “model-aware”, the “model-agnostic” model based upon M5P trees [1] has several features that address these drawbacks. It’s main difference from the classic tree is it’s use of pruning, in which the tree is first expanded to it’s maximum size and then “pruned” to remove any nodes that do not improve upon the performance of the model. In addition to this, the M5P tree uses a standard deviation split criterion in comparison to classic tree which makes a model evaluation at each split candidate as seen above.
Performance
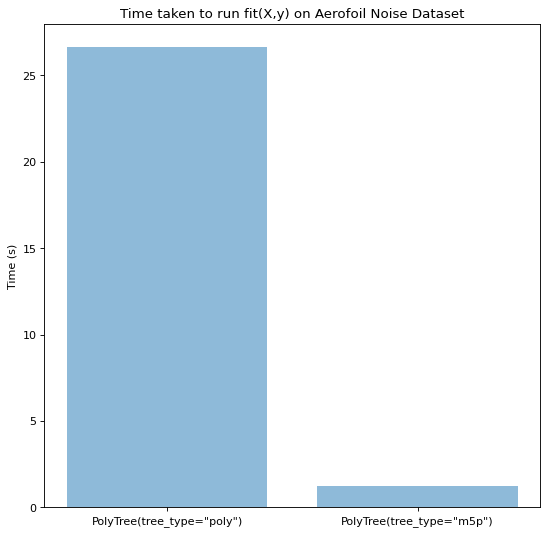
After seeing the potential of using pruning and a standard deviation criterion we decided to implement a tree_type parameter for PolyTree which would allow a user to choose tree_type="m5p". To evaluate this new tree type we decided to use the aerofoil noise data-set [2] which has 1503 samples and 4 features. As seen below the time taken to fit the model ran over an order of magnitude faster on the m5p than the polynomial split criterion, confirming our belief that the long run times of the original PolyTree were down to the fact that it had to fit thousands of polynomials during the splitting stage.
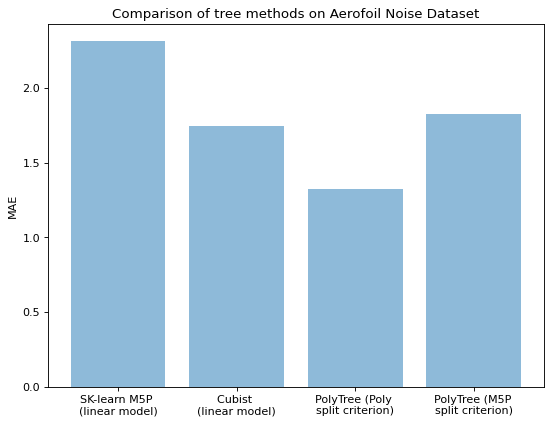
Despite the large improvement in training time, there is a trade-off in performance as seen below. Our model’s error is roughly in between the classic PolyTree performance and SK-learn’s linear M5P model. We hope that the inclusion of the M5P model in the PolyTree class will provide an option for users who wish to perform initial exploratory analysis on a data-set before running the classic PolyTree model.
Notebooks Used:
![]()
[1] Wang ,Y., Witten, I. H.: Induction of model trees for predicting continuous classes. In : Poster papers of the 9th European Conference on Machine Learning, 1997. Inducing Model Trees for Continuous | Semantic Scholar
[2] https://archive.ics.uci.edu/ml/datasets/Airfoil+Self-Noise