Hi EQuadratures Team,
I’m very much enjoying the code, thanks for all your hard work on it! I spoke with PSesh briefly about something I was trying to do, which is to find quadrature points across a regular hexagon which would allow me to interpolate nonlinear functions as accurately as possible.
To take an example in 1D, let’s say I have four points on the line, and the values of the function (q) at those points. Then, I can easily fit a third order polynomial q = p_3(x) through them. Now, I want instead to fit a function f = q^2 through the points. This necessarily involves truncating the true p_3(x) * p_3(x) = p_6(x) polynomial to a third order polynomial, and produces some aliasing error. It seems like the location of the points have a significant influence on the level of this aliasing, and that the Gauss-Legendre points work in practice very well for keeping it down in one dimension, or in two with tensor product elements.
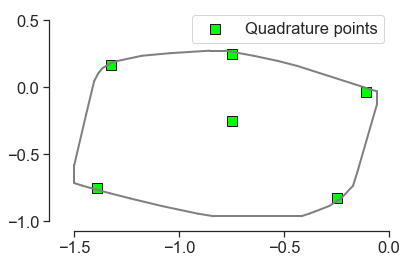
I was wondering if you had any ideas for how the 2D point locations should be laid out on the (interior of the) hexagon to achieve a similar effect? PSesh said that it would be useful to have the linear inequalities which define the interior of the hexagon, so I’ve laid them out below:
%% ===============================
% y <= RHS
y1 <= 2 * 3^(1/2) - 3^(1/2) * x;
y2 <= 3^(1/2);
y3 <= 3^(1/2)*x + 2 * 3^(1/2);
% y >= RHS
y4 >= - 3^(1/2) * x - 2 * 3^(1/2);
y5 >= -3^(1/2);
y6 >= 3^(1/2) * x - 2 * 3^(1/2);
%% ===============================
In an ideal world, the points would also have rotational symmetry of order six, so that the orientation of the hexagon didn’t affect the answer you end up with.
I’d be very grateful for any suggestions you might have!
All the best,
Rob