This blog post describes and justifies the implementation of a new regression method for Effective Quadratures (EQ). We hope to make it clear the cases in which polynomial regression trees would be well suited, as well as highlight some of the drawbacks associated with this method.
Currently in EQ, global polynomial regresssion has been implemented. This method provides the ability to quickly generate a surrogate model that is robust to noise in the training data as demonstrated below. On the other hand it performs poorly with functions such as:
- Discontinuous functions
- Polynomial functions with a order change
In order to justify these claims we use Anson Wong’s model tree with the EQ Poly class as the model. It should be noted that for simplicity a few restrictions have been made. The main restriction made is that a fixed order of 3 is chosen for all polynomials in the following examples. Additionally all example datasets are 1 dimensional for the purpose of visualisation.
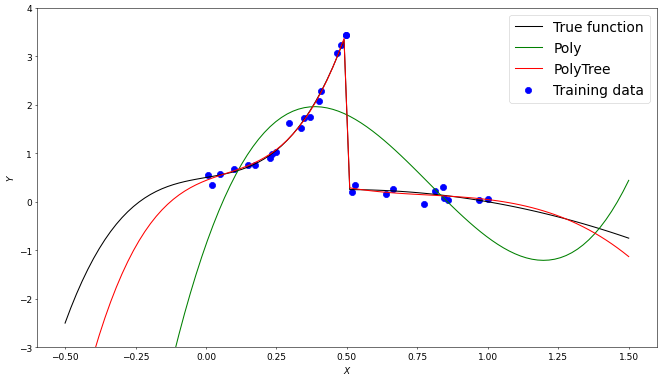
A discontinuous function $f(x)$ with $x \in [0,1]$ is constructed from two polynomial functions with added noise. Using 30 training samples from the function we can see the PolyTree is able to identify the break between the functions, resulting in signifigantly less error when compared to the global Poly approximation
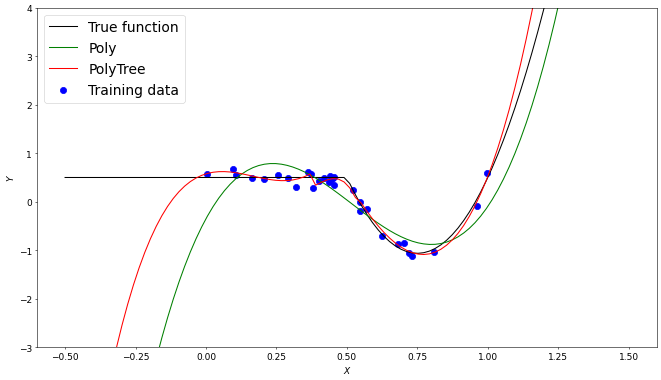
Another function $g(x)$ with $x \in [0,1]$ is constructed from two polynomial functions with added noise. The two polynomial functions have different orders and, along with the previous example, demonstrate the ability for the tree to adapt to functions with several functional forms.
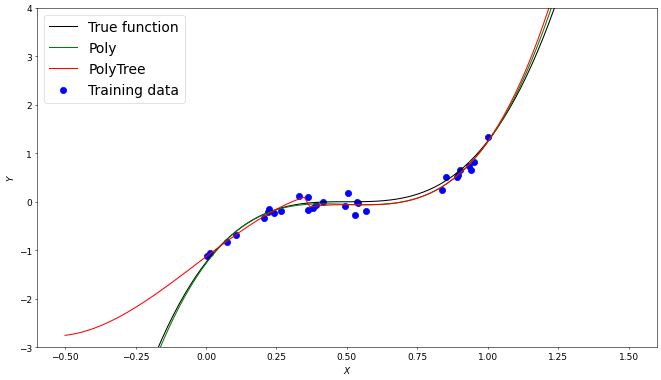
One limitation of the polynomial tree method is that as the training data is split into smaller regions for the individual polynomial models, overfitting becomes more likely. A demonstration of this is seen below, where the global Poly method approximation is relatively robust to an outlier at $(0,1)$ in comparison to the tree method, which is significantly skewed.
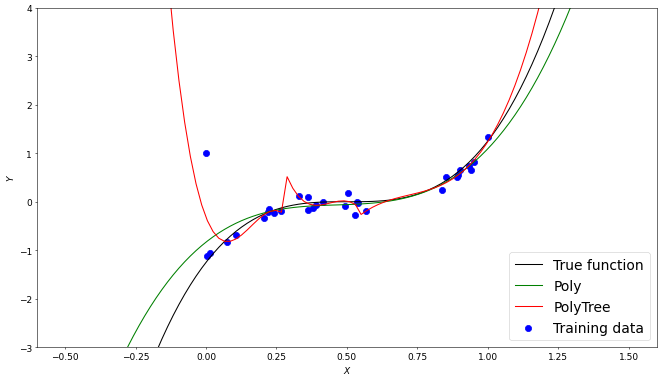
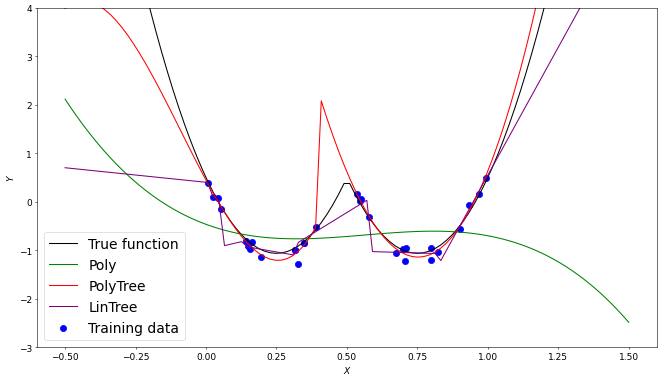
Another comparison to be made is one between a linear and polynomial regression tree. The main reason we would not want to implement a linear regression tree is that the functions we want to model are very rarely linear. Due to this linear model trees will require a greater depth and as mentioned in the previous example, a greater depth will generally result in more overfitting. In the following example we adjust the hyperparameters of the linear tree so that its model has roughly the same error as the polynomial model. This results in 7 seperate linear models compared to the 2 polynomial models used.
Conclusion and future plans
In this blog we have demonstrated the benefits of implementing an orthogonal polynomial regression tree class in EQ, as well as highlighted examples in which it would not be a suitable model to use. Over the coming weeks we will compare various approaches for deciding where to “split” the tree.
All code used to generate the above figures are avaliable at blogs/motivation-blog.ipynb at 6c9b41ba80d8cf19462b8203b74ecfcac474fd5f · barneyhill/blogs · GitHub
