Continuing on from our last post (Regression using polynomial trees) this blog post will describe the progress made in implementing a first release for the polynomial tree class in Effective Quadratures. Over the last few weeks we have gone from the limited notebook prototype to polytree.py which contains the PolyTree class with numerous additional features.
Structure
In it’s current state PolyTree can handle any n-dimensional input vector and can do so in reasonable time. Below is an example of the typical usage of a PolyTree object.
import numpy as np
from equadratures import polytree
tree = polytree.PolyTree()
X = np.loadtxt('inputs.txt')
y = np.loadtxt('outputs.txt')
tree.fit(X,y)
PolyTree Parameters
Currently the class has support for 6 different hyper-parameters which currently need to be adjusted in order to prevent over-fitting while still optimising for loss. We have also added a logging system which can be activated via the logging parameter and allows us to construct animations like the ones below.
- max_depth (int) – The maximum depth to which the tree will search to.
- min_samples_leaf (int) – The minimum number of samples per leaf node.
- order (int) – The order of the generated orthogonal polynomials.
-
basis (str) – The type of index set used for the basis. Options include:
univariate,total-order,tensor-grid,sparse-grid,hyperbolic-basisandeuclidean-degree; all basis are isotropic. -
search (str) – The method of search to be used. Options include
uniformandexhaustive -
samples (int) – The interval between splits if
uniformsearch is chosen - logging (bool) – Actions saved to log
GraphViz Support
The method get_graphviz has been implemented in order to help the user visualise their generated trees. As GraphViz requires a system application to render graphs, a url to an online renderer is instead given so that the number of dependencies of Effective Quadratures can be reduced.
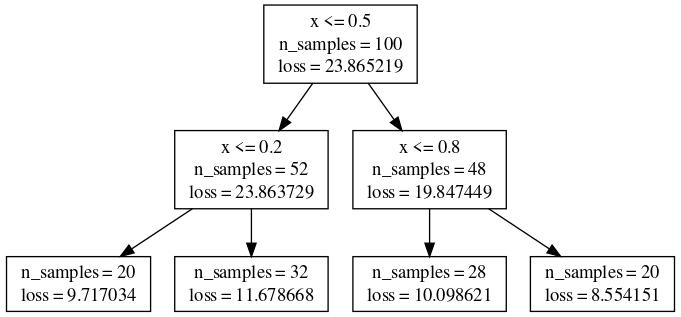
Splitting Trees
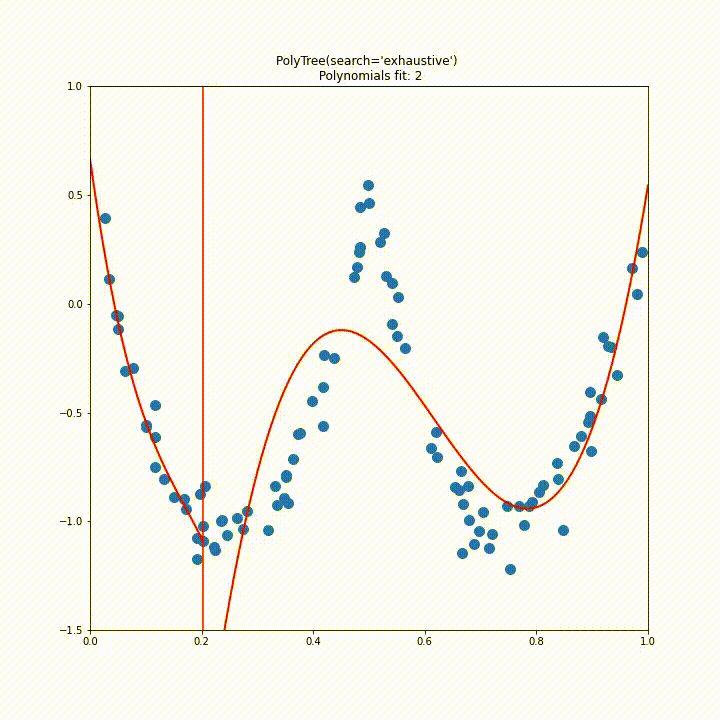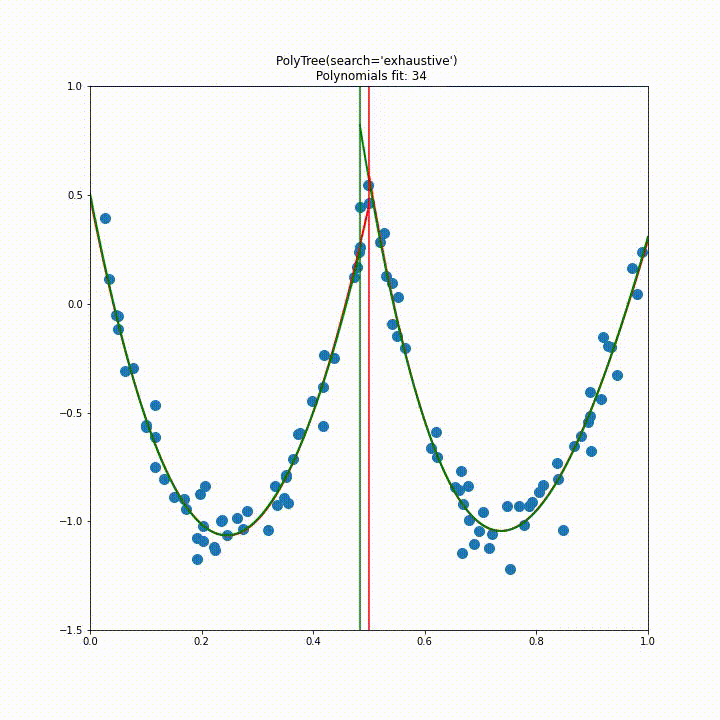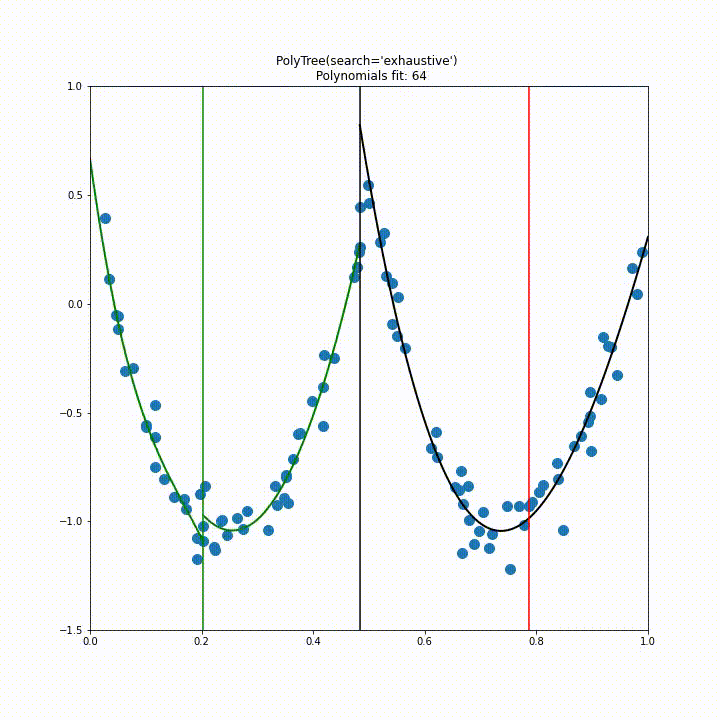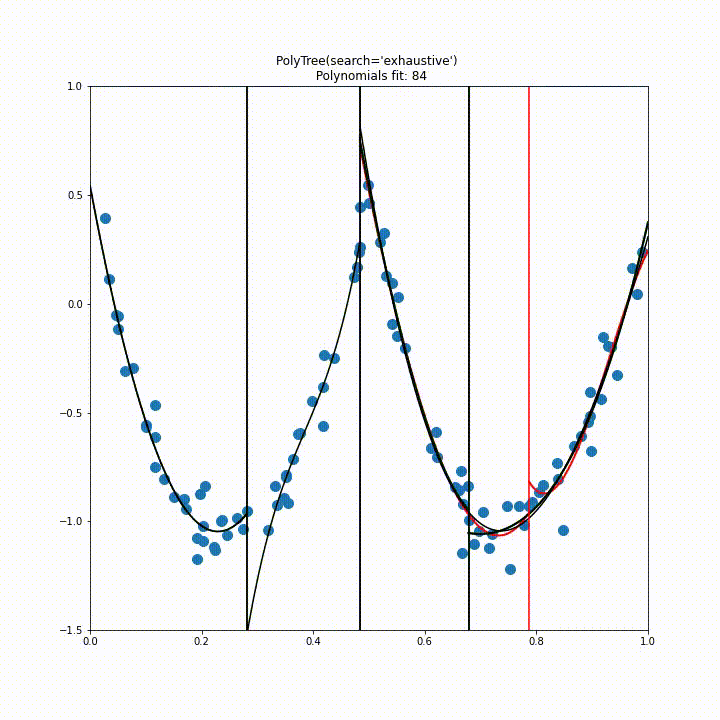
Perhaps the most important part of the Polynomial Trees implementation is how we decide to split the tree. Our first approach to this was to test a split at every training point along every feature axis, eventually splitting when the combined loss was minimised like so.
FOR point IN data
left, right = temp_split_data(point)
loss_left, loss_right = fit_poly(left), fit_poly(right)
loss = ( count(left) * loss_left + count(right) * loss_right ) / count(data)
IF loss < best_loss THEN best_loss = loss
Below is the result of this splitting algorithm running on a single feature dataset. The green lines indicate the best split found, the red indicates the current line being accessed and the black indicates the final decided splits.
Again we repeat this visualisation for a dataset with two features generated by $f(x_1, x_2) = \exp{(X-(x_1^2+x_2^2))}, \text{ with } X \sim N(0,1)$. From this animation it is quite clear that the initial approach to splitting would be impractical for higher dimensions.
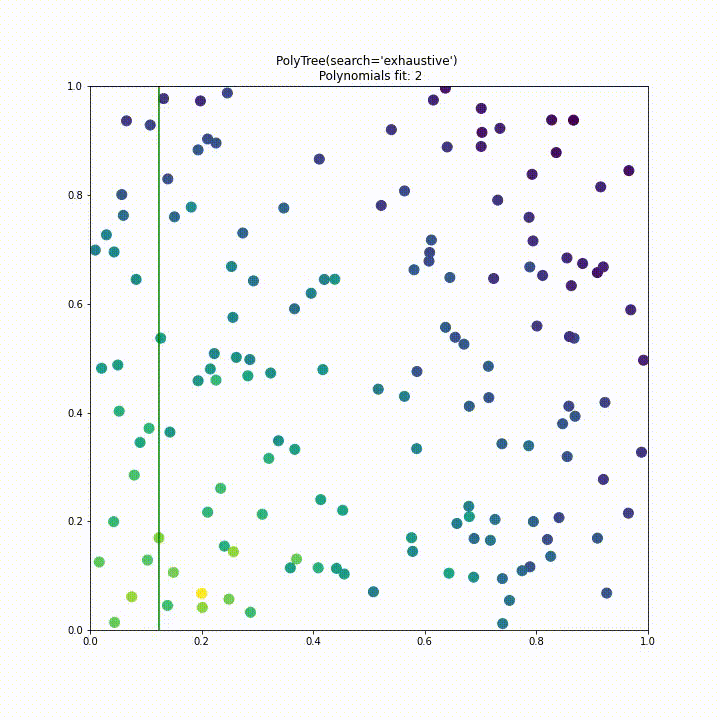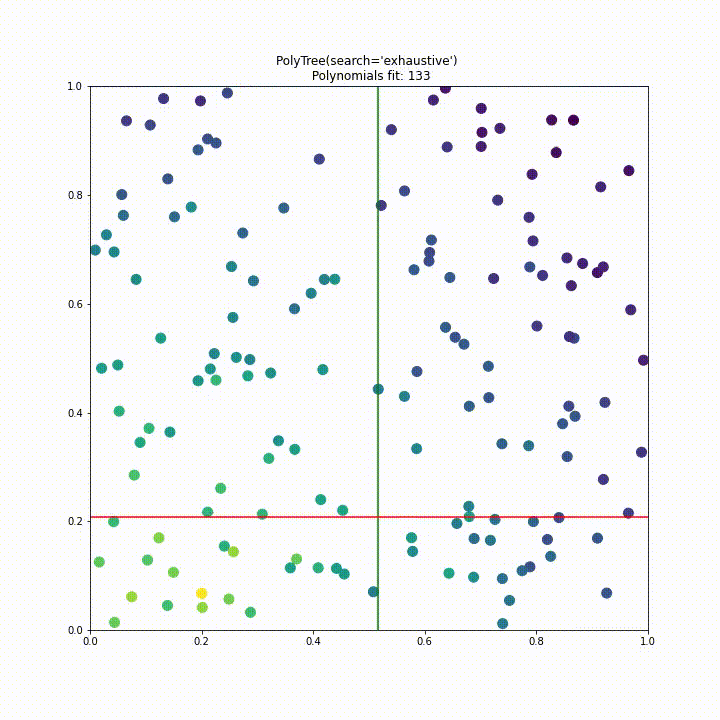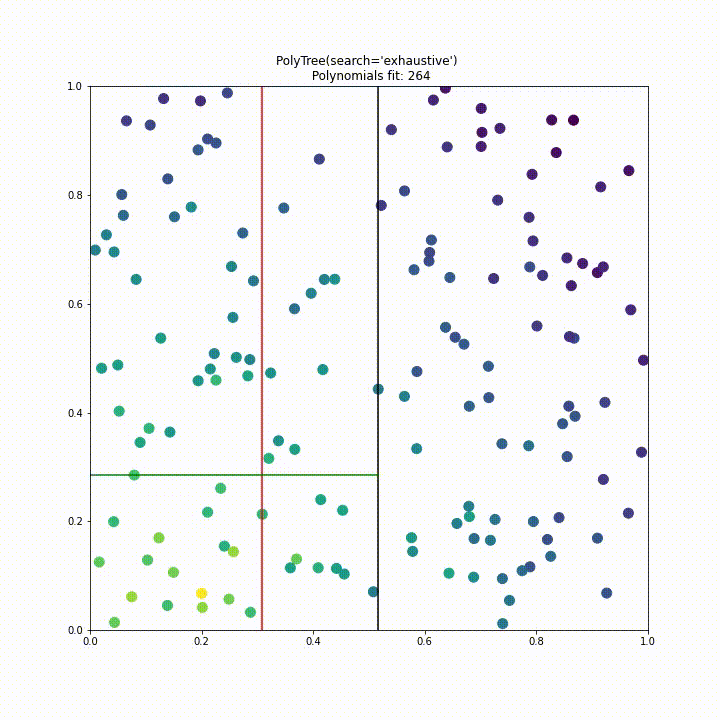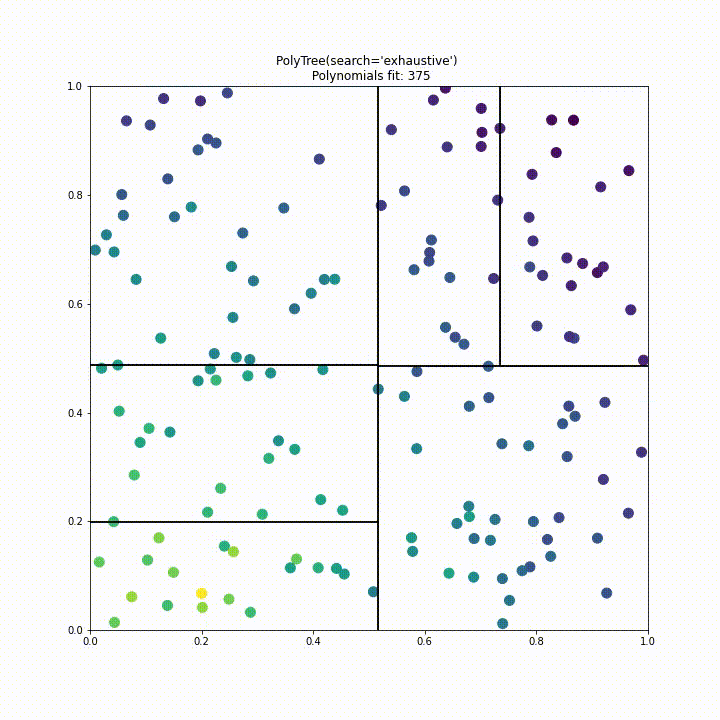
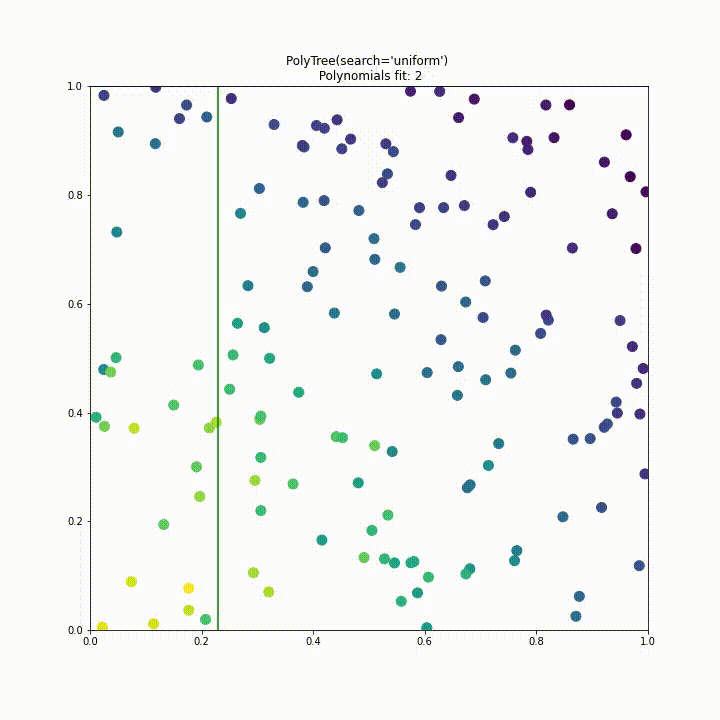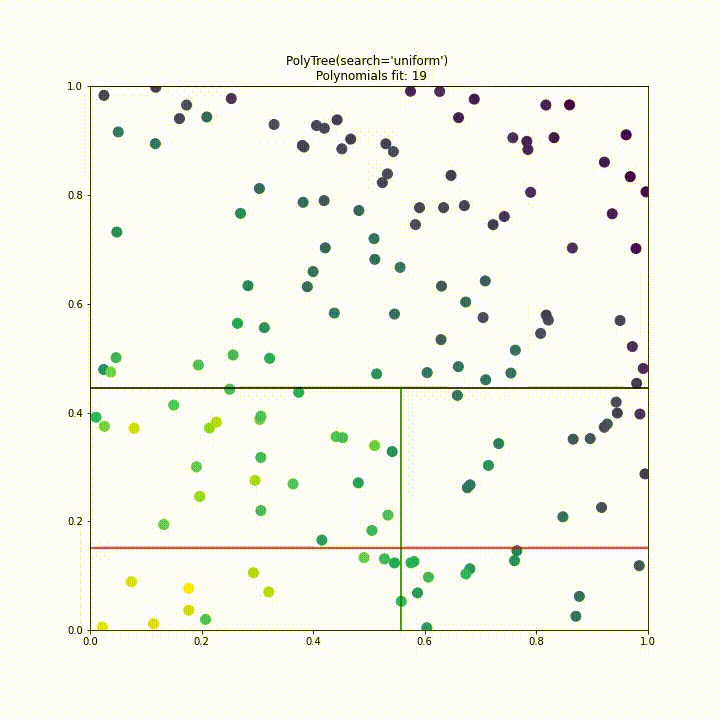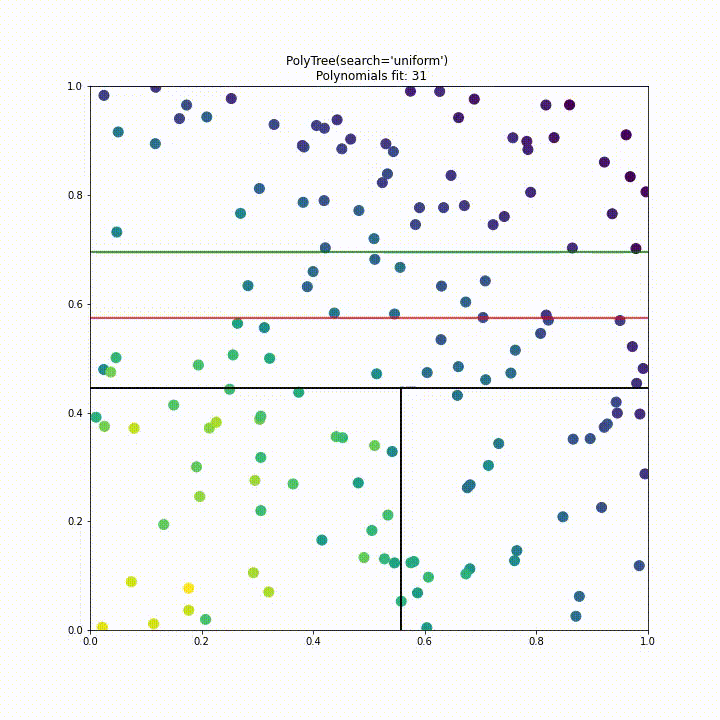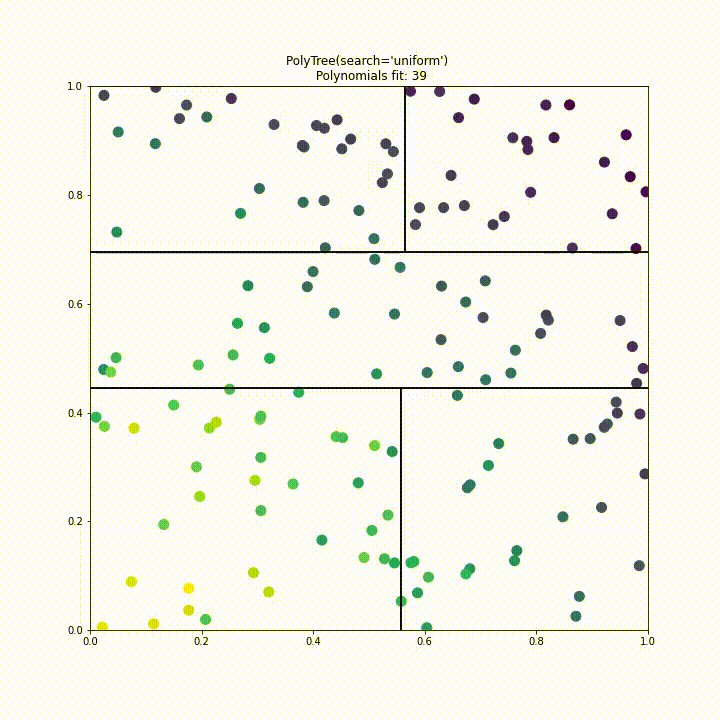
To improve performance we have implemented a “uniform” split search type. Instead of testing a split at every point of data in every dimension we instead divide the search space into a fixed number of segments where the fixed number is decided by the samples parameter like so polytree(search='uniform', samples=25). This approach significantly improves performance over the previous approach, in this case requiring 6 times less polynomial fits while having comparable performance.
Future improvements
- Improving the search algorithm - Real-world datasets, with greater numbers of dimensions/features and outliers, may pose challenges for the exhaustive and uniform search algorithms. We are exploring alternative splitting algorithms, such as derivative free line searches, to improve performance here. Implementing gradient boosted tree’s is another exciting possibility.
- Improving polynomial fits - Harnessing the existing functionality in Effective Quadratures to further improve performance. For example, compressed sensing might allow us to reduce the amount of training data required.
- Hyper-parameter tuning - Automated tuning of hyper-parameters (such as max_depth) by incorporating a complexity term into the loss function.
- Extending functionality - Examining how to compute moments (and sensitivity indices) for piecewise polynomials. This would allow the PolyTree’s to be used for uncertainty quantification and sensitivity analysis. Exploring how to obtain smooth piecewise polynomials (or even smooth derivates) may also be of value.
This blog was written as part of Google Summer of Code. Many thanks to @Nick, @ascillitoe @psesh for being such great mentors.
Code used to generate figures:
![]()